在 PostgreSQL 技术群里,今天发现有个人在群里“求救”,说想要执行一条SQL语句,获取某表中以某字段为组,并且sum(其他字段)结果最小的,所有结果。
比如,有张表如下:
|
|
想要的结果是,以path所有相同的字段分组,并且 sum(cost)字段,选择出sum(cost)值最小的,所有path字段。如:
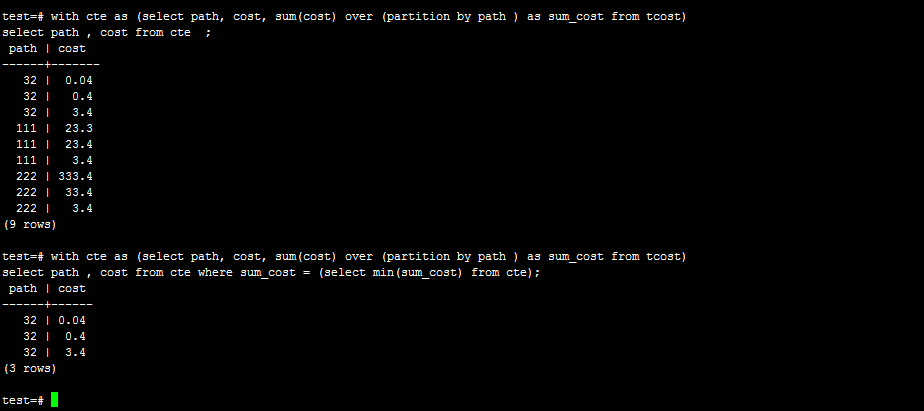
我写的SQL:
|
|
我的解题思路
在没有接触到PostgreSQL之前,我一直使用MySQL,每次想到“组”这个字,总会想到 group by 。虽然可能使用group by 也可能实现相同的结果,但是经常需要表自身join表,所以性能方面对于数据量大的表话,是满足不了要求的,即使是有索引。因为索引最适合于那种存在索引,而且选择率低的表,否则的话,索引的优势其实和全表扫描差不多,甚至有时候,常常是全表扫描比索引的全表扫描性能还要好。(当然,在PostgreSQL中,如果是只读索引来扫描的话,性能是最好的)。因为MySQL的 InnoDB 是索引组织表,所以索引全表和普通的全表扫描,性能几乎是没有差别。但是在PostgreSQL中,这种差别就很明显了,选择率大的索引全表扫描,比顺序全表扫描SeqScan慢好多。
说远了,回到题目上来。这思路虽然也是要分组,但这种分组跟group by 的分组差得比较远,这种需要一种“窗口函数”(Window Function,在Oracle里叫分析函数)来处理这钟需求,而且这种窗口函数的性能是比那种需要自表连接的性能快好多的,即使是没有索引情况下。之前在群里也遇到这种情况,利用窗口函数几秒钟就可以出结果,但那种自连接的(特别在数据量大的情况下)要几十分钟。这种窗口分组来处理数据,可以避免好多性能问题,而且非常易于理解。
所以,对于PostgreSQL,一有那种需要那种类似窗口的分组操作,首先要想到 Window Function,真的是非常好用。