问题:
我正从事Java的工作.我通常如下设置一些对象:
|
|
问题是:someName在这个例子里等于null,我是否可以可靠地为所有对象假设为空检查未初始化对象,这是否准确?
最佳回答:
正确,在Java里所有引用类型的静态以及实例成员,没有显式地初始化的,都会被设为null.这个规则同样适用于数组成员.
从Java语言规范, 4.12.5部分可知:
|
|
注意,以上规则不包括局部变量:它们必须显式地初始化,否则程序不会被编译.
问题:
我正从事Java的工作.我通常如下设置一些对象:
|
|
问题是:someName在这个例子里等于null,我是否可以可靠地为所有对象假设为空检查未初始化对象,这是否准确?
最佳回答:
正确,在Java里所有引用类型的静态以及实例成员,没有显式地初始化的,都会被设为null.这个规则同样适用于数组成员.
从Java语言规范, 4.12.5部分可知:
|
|
注意,以上规则不包括局部变量:它们必须显式地初始化,否则程序不会被编译.
主要功能如下:
主要特性
因为规范里的 HttpSession 以及 HttpServletRequest 都是一种接口,所以可以通过实现该接口来处理我们自定义的逻辑。
Spring Session里的自定义实现HttpServletRequest的逻辑代码:
|
|
HttpServletRequestWrapper是HttpServletRequest实现的一种包装器,可通过继承它来实现自己的主要逻辑代码,而不用直接实现HttpServletRequest接口来写大部分复杂的代码,只需要关注自己想要覆盖逻辑代码即可。
在这里,因为我们想要实现的是Session共享机制,所以这里只加入了处理Session的业务逻辑即可。
Spring Session默认情况下只有两种Session策略。一种是使用Map来实现,一种是使用Redis来实现。
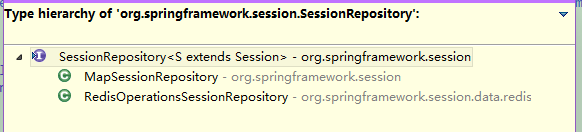
如果我们想要实现自定义的Session持久化机制,我们可以实现该接口,然后添加到Session策略实现方式即可。
包装完自定义的HttpServletRequest后,就可使用了。方法是通过 Filter 来将Spring包装的HttpServletRequest代替容器原有的即可。代码如下:
|
|
|
|
web.xml 添加以下 Filter
|
|
spring.xml 添加
|
|
使用上跟普通使用 Session 的方式是一样的。
打完收工。
实现也很简单,只需要一个一维数组和一个指向栈顶的变量 top 就可以了。我们通过 top 来对栈进行插入和删除操作。
|
|
规则是这样的:首先将第 1个数删除,紧接着将第 2 个数放到这串数的末尾,再将第 3 个数删除并将第 4 个数放到这串数的末尾,再将第 5 个数删除……直到剩下最后一个数,将最后一个数也删除。按照刚才删除的顺序,把这些删除的数连在一起就是小哈的 QQ啦.
例如:加密过的一串数是 “6 3 1 7 5 8 9 2 4”,输出应该是“6 1 5 9 4 7 2 8 3”
|
|
每次排序的时候设置一个基准点,将小于等于基准点的数全部放到基准点的一边,将大于等于基准点的数全部放到基准点的另一边.
因此快速排序的最差时间复杂度和冒泡排序是一样的,都是 O(N^2 ),它的平均时间复杂度为 O(NlogN)。
|
|
冒泡排序的基本思想是:每次比较两个相邻的元素,如果它们的顺序错误就把它们交换过来。
以从大到小为例。
每次都是比较相邻的两个数,如果后面的数比前面的数大,则交换这两个数的位置。一直比较下去直到最后两个数比较完毕后,最小的数就在最后一个了。就如同是一个气泡,一步一步往后“翻滚” ,直到最后一位。所以这个排序的方法有一个很好听的名字“冒泡排序” 。
每将一个数归位我们将其称为“一趟” 。每一趟,都是将小的归位(先是最小,后次小,次后第三小…)。
如果有 n 个数进行排序,只需将 n-1 个数归位,也就是说要进行n-1 趟操作。而“每一趟”都需要从第 1 位开始进行相邻两个数的比较,将较小的一个数放在后面,比较完毕后向后挪一位继续比较下面两个相邻数的大小,重复此步骤,直到最后一个尚未归位的数, 已经归位的数则无需再进行比较 (已经归位的数你还比较个啥, 浪费表情) 。
冒泡排序的核心部分是双重嵌套循环。
|
|
冒泡比较耗时
M:桶的个数(也是该数值的最大数)
N:待排序个数
随便输入N个不大于M的数字,然后从小到大输出:(从大到小,作一下小修改即可)
|
|
这种算法适合于范围比较小的排序,并且是需要知道输入的最大值。不然就不适用了。
|
|
|
|
在自己写的一段代码中,使用到了Redis。代码的逻辑是这样子的,先取出数据,然后判断,再然后将该数据进行自减。代码如下:
|
|
在提交代码的时候,总监复查代码时,提出这段代码可能在并发的时候出现问题:比如有两条线程,都进入到了if(sub){xxx}这段代码,这个时候,就造成了重复多次自减的问题。比如,如果该value是5,那应该减到0就不会再减了,但是这段代码在高并发情况下,可能会出现减到-1的情况。这虽然对于现有的业务影响不大,但是,如果是对于其他的一些比较敏感并且需要精确的数据时,就需要特别注意了。
关键是之前一直没有怎么意识到这段代码可能会造成的问题。之前一直认为,对于局部变量是不会出现多线程问题的,这倒是没有错,但关键是如果是从其他地方传过来而且在多处地方允许被使用的情况下,就需要注意多线程问题。
因为 String 和 Integer 不是在同一个对象阶层。
|
|
当你尝试强制转换时,仅仅会在同一个对象阶层转换。比如:
|
|
在这种情况,(A)objB 或者 (Object)objB 或者 (Object)objA 可以进行转换。
正如其他人已经提到,将integer转换成String可以使用以下方法:
基本类型的整型时使用:String.valueOf(integer)或者Integer.toString(integer) 来转换成String。Integer对象型时使用:Integer.toString()转换成String
写代码过程中,居然遇到这种错误(在使用Spring 来操作 Redis 经常出现,但百思不得其姐。和同事讨论时才发现,原来Redis在底层永远是保存String的,即使在写代码的时候是写成 set(String, Object)。这时,如果get这个缓存出来,而且想要的是整型时,就会报java.lang.ClassCastException: java.lang.Integer cannot be cast to java.lang.String错误。),出来工作差不多2年了,这种错误的本质原因,直到今天才明白。实在是太惭愧了。很可能是被所有对象可以以字符串的形式表示而导致的,以为所有的对象在使用 (String)obj时,会使用 obj.toString(),所以才造成这种认为理所当然的错觉。