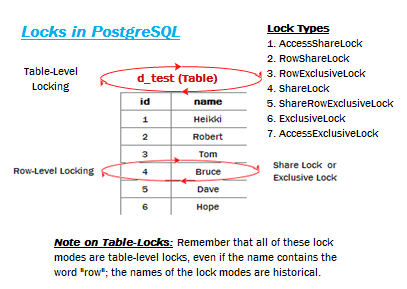
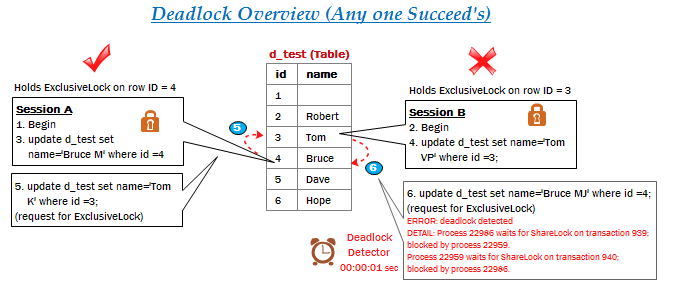
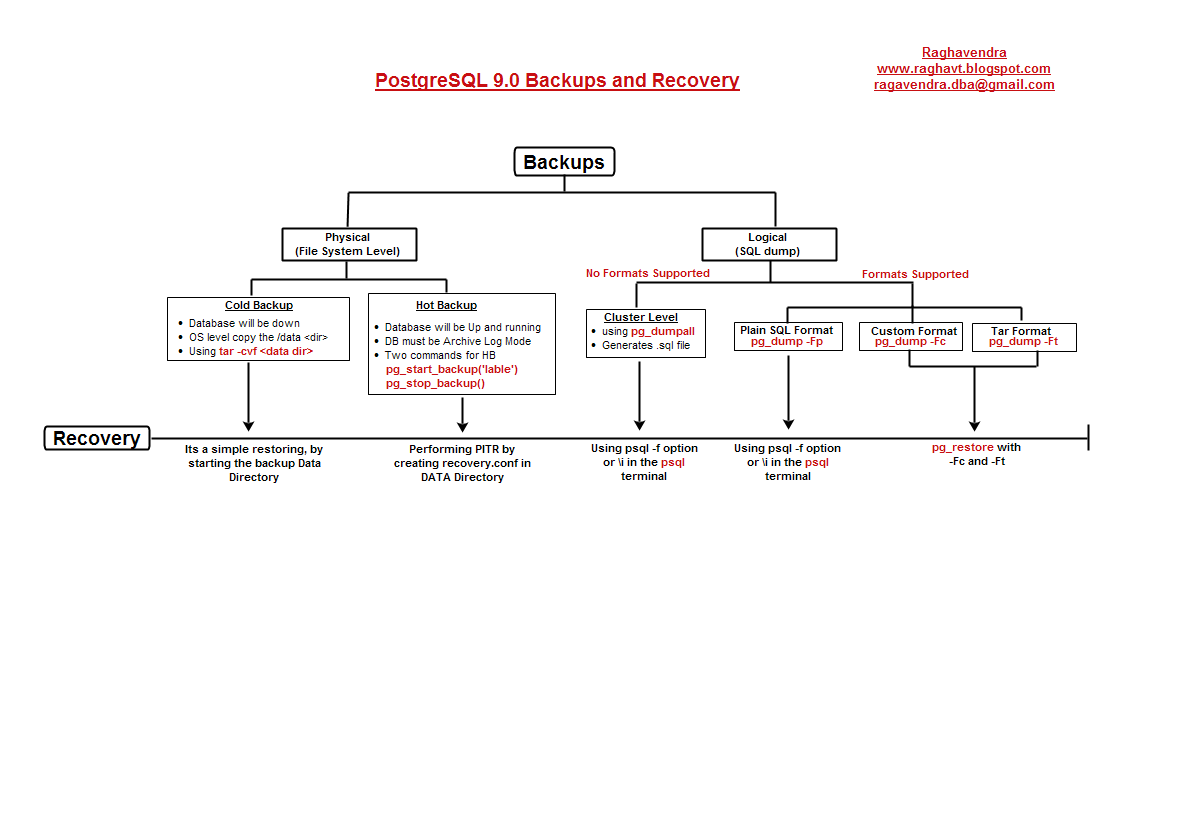
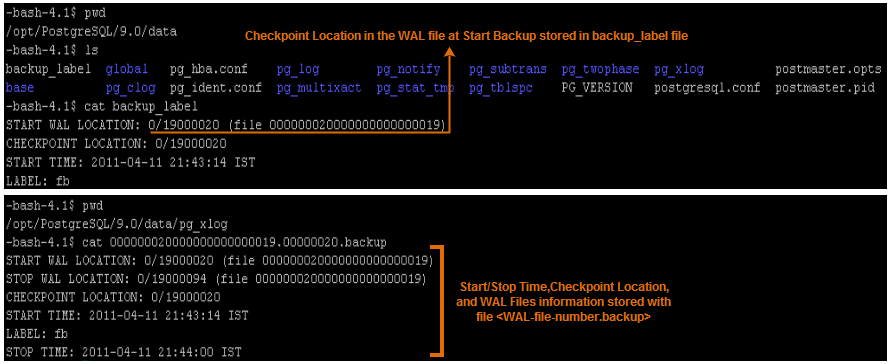
有许多原因导致为什么Postgres查询计划没有选择使用索引。大多数的时候,查询计划器是正确的,即使它不是那么明显地为什么会这样。 如果相同的查询有几次会使用索引扫描,但其他时候不使用索引扫描,这是没问题的。从表中检索到的行数可以基于特定的常数值的查询检索而变化。(我注:即不同的常量值,会导致不同的结果行数)。因此,例如,查询计划器对于查询select * from foo where bar = 1使用索引可能是正确的,但对于查询select * from foo where bar = 2却可能不使用索引,这发生于对于bar值为2的行有比较多的话。发生这种情况时,顺序扫描实际上是最有可能比索引扫描快得多,因此,查询计划器实际上是判断正确的,这时顺序扫描的性能代价相比索引扫描更低。
虽然Postgres已经能够创建多列索引,重要的是要理解这样子做的意义。Postgres查询计划器通过位图索引扫描(bitmap index scan)在一条多列查询中有能力结合和使用多个单列索引。通常,你可以在覆盖查询条件的每个列上创建索引并且大部分情况下Postgres将会使用到它们,所以在你创建一个多列索引之前做一个基准测试并证明创建一个多列索引是有效的。正如之前一样,索引是有代价的,并且一个多列索引仅能在查询引用的列是与创建索引时的列的顺序是一样的才会被优化,虽然多个单列索引提供大量的查询的性能改进。
然而在某些情况下,一个多列索引显然是有意义的。一个在列(a,b)上的索引能够用在查询包含WHERE a = x AND b = y,或者查询仅使用WHERE a = x的情况,但是不会用于查询使用WHERE b = y的情况。所以,如果这匹配到你的应用程序的查询模式,多列索引就是值得考虑的。也要注意在本例中创建一个独立的索引(我注:我理解是在这种情况下,创建多个单列索引)是多余的。
当你准备在你的生产数据库上应用一个索引时,请记住创建索引会锁表并阻塞写操作。对于大表,这可能意味着你的网站是停机几个小时。幸运的是,Postgres允许你CREATE INDEX CONCURRENTLY(并发创建索引),这会导致花更多的时间来建索引,但是不要求锁住写锁。正常的CREATE INDEX命令要求一个锁来锁住写操作,但允许读。最终,在之后一段时间,索引会变得碎片和未优化,如果在表中的行经常更新或删除就特别容易这样。在这种情况下,就可能需要执行一个REINDEX命令来平衡及优化你的索引了。然而,要谨慎重建索引会在父表中获得写锁。有个策略在在线的网站来实现相同的结果就是并发地在相同的表和列但有一个不同的名称的索引,然后,删除旧的索引并且重新命名新的索引。这个过程可能持续比较久,但不要求在在线的(活跃)表有任何长久执行的锁。当准备创建B树索引时Postgres提供了许多灵活性来优化你特定的使用情况,也有许多选项来管理你应用程序不断增长的数据库。这些建议应该会帮你保持你的数据库健康,以及你的查询非常爽快。
\set locks 'SELECT w.locktype AS waiting_locktype,w.relation::regclass AS waiting_table,w.transactionid, substr(w_stm.current_query,1,20) AS waiting_query,w.mode AS waiting_mode,w.pid AS waiting_pid,other.locktype AS other_locktype,other.relation::regclass AS other_table,other_stm.current_query AS other_query,other.mode AS other_mode,other.pid AS other_pid,other.granted AS other_granted FROM pg_catalog.pg_locks AS w JOIN pg_catalog.pg_stat_activity AS w_stm ON (w_stm.procpid = w.pid) JOIN pg_catalog.pg_locks AS other ON ((w.\"database\" = other.\"database\"AND w.relation = other.relation) OR w.transactionid = other.transactionid) JOIN pg_catalog.pg_stat_activity AS other_stm ON (other_stm.procpid = other.pid) WHERE NOT w.granted AND w.pid <> other.pid;;'
test=# with RECURSIVE commenttree (comment_id, bug_id, parent_id, author, comment, depth) as (select comment_id, bug_id, parent_id, author, comment , 0as depth from comments where parent_id isnullunionallselect c.comment_id, c.bug_id, c.parent_id, c.author, c.comment, ct.depth+1as depth from commenttree as ct join comments as c on (ct.comment_id = c.parent_id)) select * from commenttree where bug_id = 1;;