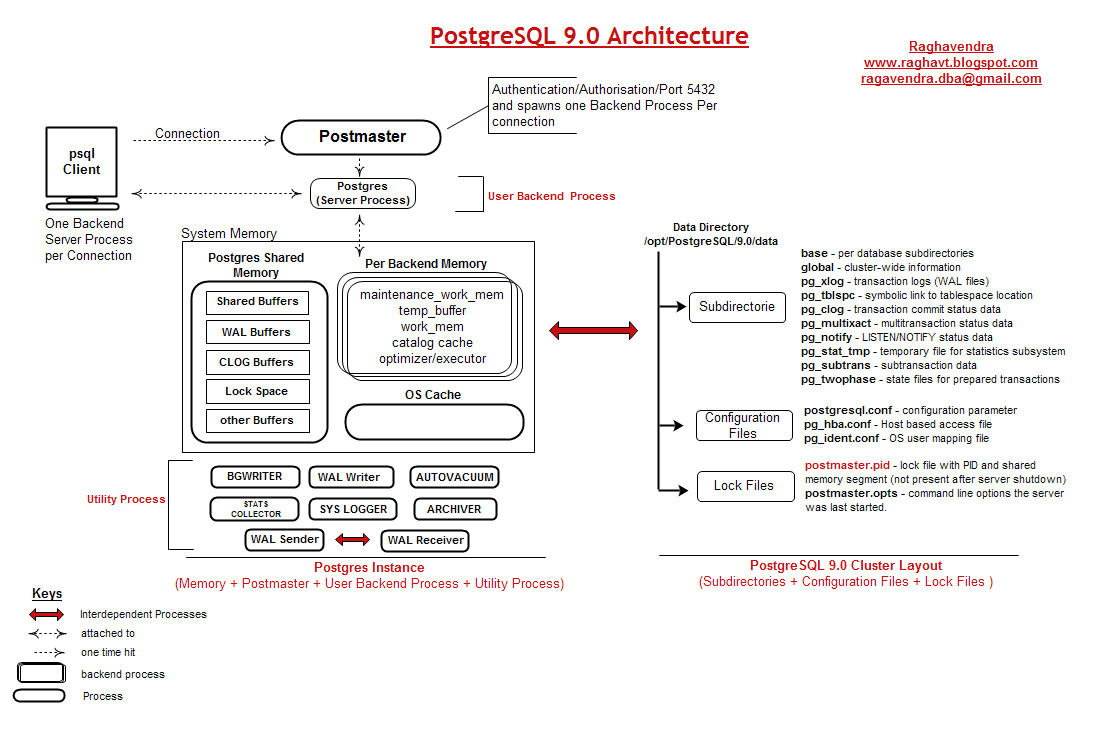
在PostgreSQL,备份和恢复相对于其他的数据库是非常友好的。许多人也许不赞同,但我们不要陷入争论中。来讨论下备份,PostgreSQL不支持增量备份,然而,有许多非常统一的备份工具和操作系统级别的解决办法来实现这个目的。
我的关于PostgreSQL备份和恢复的图解给出了一个完整的概念的想法。看图,你可以辨别出哪个备份可以用来还原或恢复。
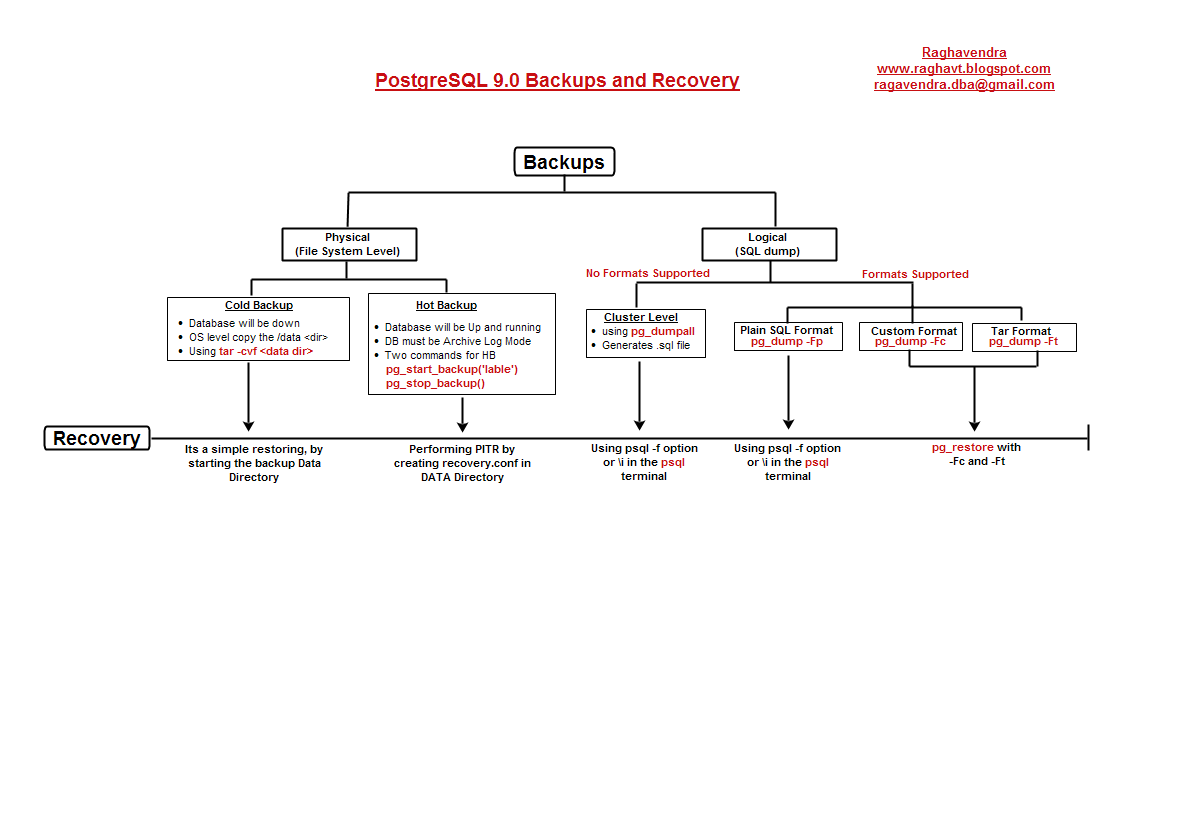
逻辑备份
pg_dump,pg_restore和pg_dumpall工具是用来进行逻辑备份的。pg_dump和pg_restore可以帮助你在数据库级别、模式级别和表级别备份。pg_dumpall用于集群级别备份。
pg_dump支持三种格式,Plain SQL 格式(纯文本SQL格式), Custom 格式(自定义格式)和 Tar格式(打包格式)。Custom和Tar格式的备份与pg_restore工具是兼容的,然而,Plain SQL(纯文本SQL)格式的备份是与psql工具兼容的用于还原。
以下是每个备份级别和相关的还原命令的例子。
注意:在.bash_profile里设置默认的PGDATABASE, PGUSER, PGPASSWORD和PGPORT值。(在Windows里意思是环境变量)
纯文本SQL格式的备份和还原
|
|
自定义格式
|
|
Tar格式
$ pg_dump -Ft dbname -f filename
$ pg_restore -U username -d dbname filename
or
$ cat tar-file.tar | psql -U username dbname
注意:模式级别和表级别备份执行方式是一样的,通过添加相关的选项就可以了。
集群级别备份
|
|
这些都是非常好的备份和恢复的方法。特别地,www.2ndQuadrant.com 出版的,作者是Simon Riggs 和 Hannu Krosing 的书: “PostgreSQL 9 Administration Cookbook - 2010”,是学习PostgreSQL备份和恢复的很好方式。
物理备份(文件系统备份)
冷备份
在冷备份中,当Postgre实例关闭时,进行一个非常简单的/data目录的文件系统备份,意思是,实现一个前后一致的数据目录备份,在复制之前,数据库服务器应该关闭。PostgreSQL通过软链接来灵活地保持pg_xlog和pg_tablspce在不同挂载点。当复制/data目录并想包括那些软链接的数据时,可以使用以下命令。
|
|
热备份(在线备份):
在热备份中,集群会一直在启动和运行,并且数据库应该是在归档日志模式中。两个系统函数将会唤醒实例来开始、关闭热备份处理(pg_start_backup(), pg_stop_backup())。在开始进一步进行在线热备前,让我们讨论一下对于在线备份中强制的数据库归档模式。
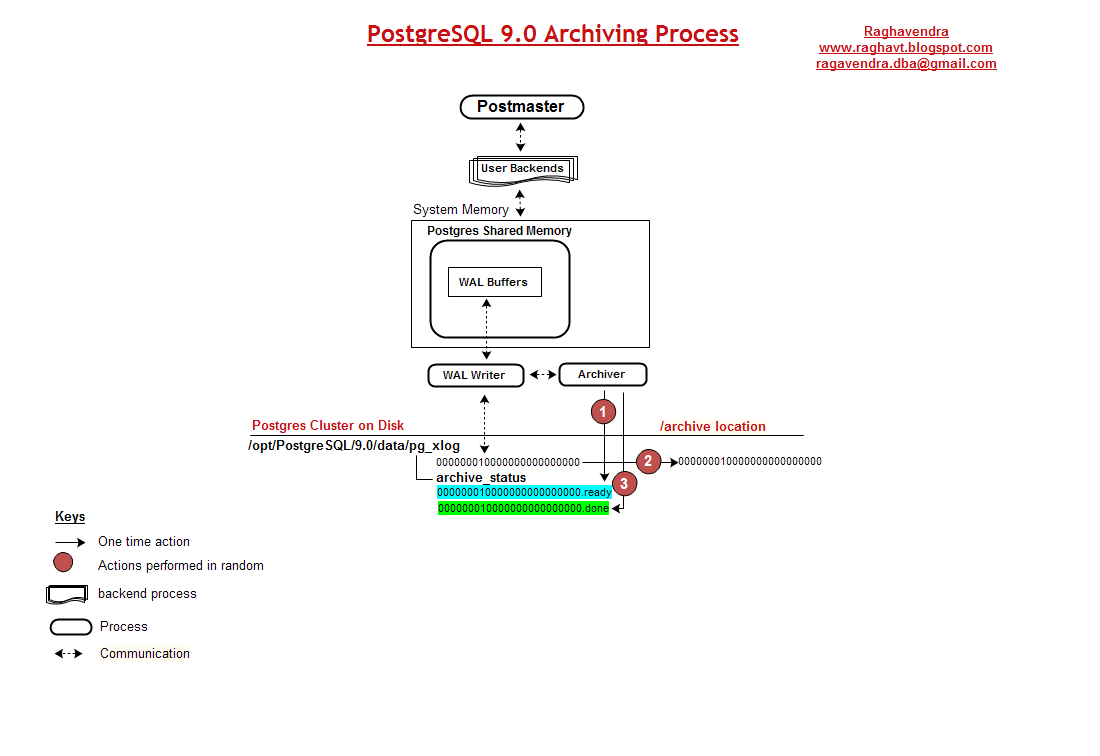
开启 WAL(预写式日志)归档:
下面将简要介绍一下 PITR/调整 WAL 等等。目前,我们先看看WAL归档。在PostgreSQL数据库系统,实际上数据库“写”一些额外被称为预写日志(WAL)文件到磁盘。它包含了一些在数据库系统中的写记录。在崩溃的情况下,数据库可以从这些记录中还原或恢复。
一般地,写日志记录会在定期匹配时(叫做checkpoints,检查点)记录该检查点,然后在它不再需要时删除它。你也可以使用WAL作为备份,因为它是一个所有数据库的写记录。(我注:就是更改数据库的操作)。
WAL归档概念:
WAL是由每16MB大小(我注:文件)组成的,这被称为segments(段)。WAL驻留在pg_xlog目录下,这是一个位于数据目录下的子目录。文件名会被PostgreSQL实例按数字升序来命名,执行一个WAL基础备份,这需要一个基础备份,一个数据目录的完整备份,并且WAL段会介于基础备份和当前日期之间。
配置WAL段归档,可以通过在postgresql.conf里的两个配置参数来设置:archive_command和archive_mode。使集群进入归档模式需要重启PostgreSQL。
|
|
注意:%p为通过路径来复制文件来作为一个文件名,%f没有为目标文件设置目录。(我注:也就是%p代表pg_xlog的绝对路径的文件,%f表示pg_xlog目录下的文件名,所以%p前没有目录,%f前有目录前缀)。
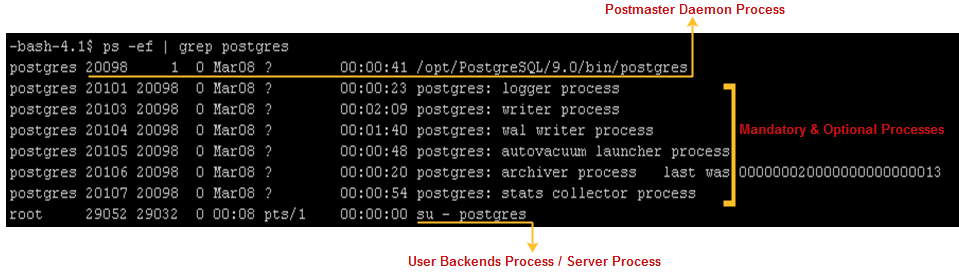
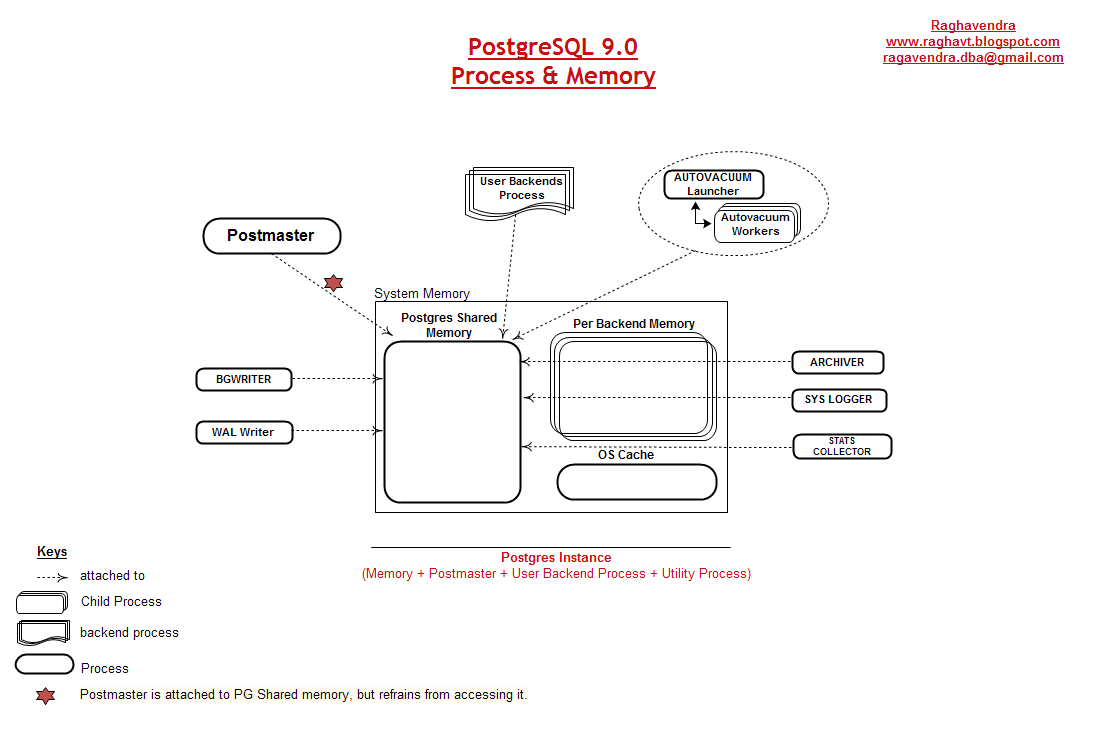
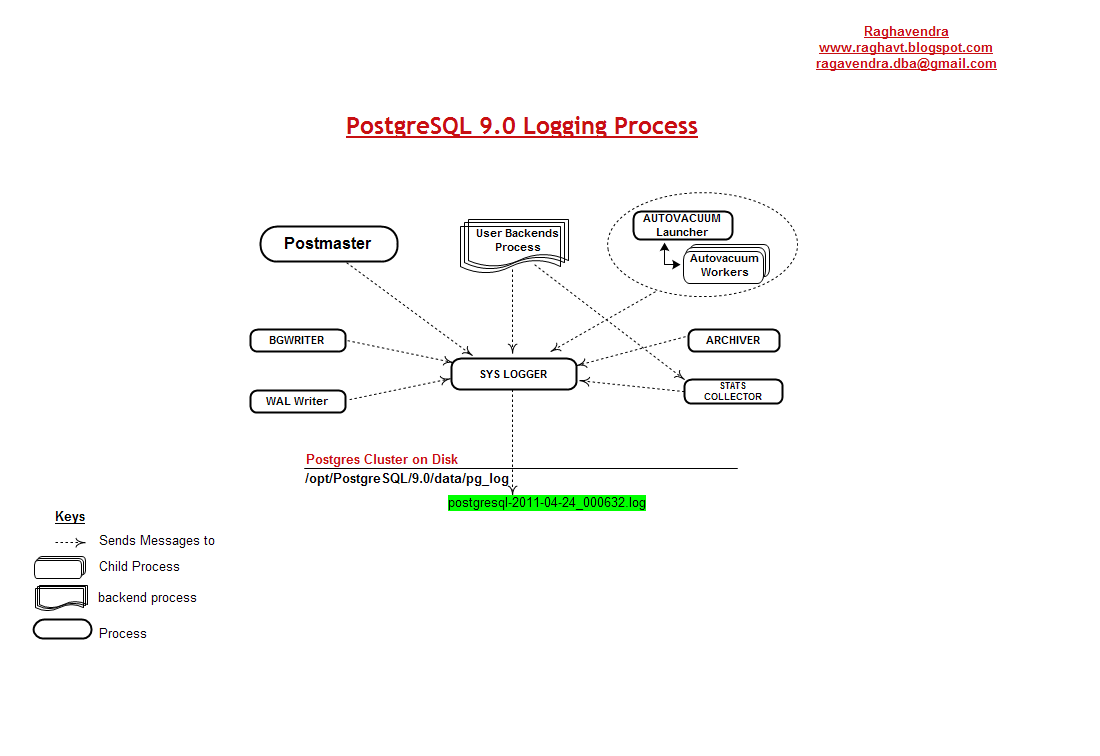
关于归档进程的更加多信息,请参考“PostgreSQL 9.0 内存 & 进程”
在线备份 :
采取在线备份:
|
|
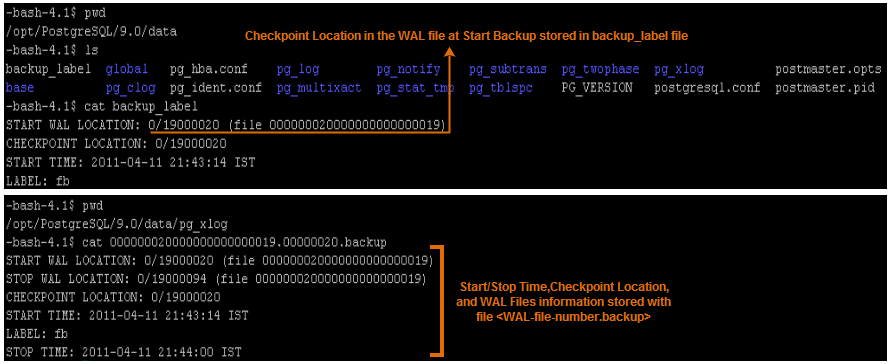
在PostgreSQL中,没有目录来保存在线备份的开始时间和结束时间。然而,当在线备份正在进行时,会有数个文件会被创建和删除。
pg_start_backup('label')和pg_stop_backup是两个执行在线备份的系统函数。通过pg_start_backup('label')会创建一个文件backup_label在$PGDATA目录下,通过pg_stop_backup()会创建一个文件wal-segement-number.backup在$PGDATA/pg_xlog目录下。backup_label会给出开始时间以及WAL(预写式日志)段的检查点位置,也会通知PostgreSQL实例是处于备份模式。在$PGDATA/pg_xlog目录下的wal-segment-number.backup文件描述了开始和停止时间,带有WAL段号的检查点位置。
注意: 在pg_stop_backup()之后,PostgreSQL实例就会删除backup_label文件。
提交你的评论,建议。
—Raghav
By Raghavendra